Neuroinformatik
Raum 04.106 / Technikum 04.003
Aktuelle Forschungsarbeiten:
Die vorhandene Ausstattung bildet die Grundlage um anwendungsbezogene Forschung und Lehre im Bereich der bildgebenden Sensortechnik, der Einzelbildanalyse, der Bildsequenzanalyse und der Szenenanalyse sowie im Bereich Akustik, Psychoakustik, Soundqualität und Sounddesign durchzuführen. Aktuelle Forschungsprojekte vertiefen die Inhalte:
- Intelligente Videotechnik / Sicherheitstechnik
- Inspektion / Qualitätssicherung
- Bildverarbeitung im Innen- und Außenraum
- Szenenanalyse
- Mensch-Maschine-Interaktion
- Datenfusion
- Geräuschanalyse
- Datenanalyse
APFEl – Analyse von Personenbewegungen an Flughäfen mittels zeitlich rückwärts- und vorwärtsgerichteter Videodatenströme
Videotaktschritthaltend werden der Kopf- (rot), Kopf-Schulter- (grün) und Ganzkörperbereiche (orange) detektiert und unter Zuhilfenahme von Low-Level-Verfahren zu einer Detektektion je Person fussioniert. Gleichzeitig werden erste Merkmale extrahiert. Nach markieren einer Person wird diese mittels multipler Entscheider (z.B. HRW-Oberkörperwiederereknnung) kameraübergreifend wieder gefunden.
Programm
gefördert durch das BMBF im Rahmen des Nationalen Sicherheitsforschungsprogramms zu der Bekanntmachung "Mustererkennung"
Projektlaufzeit
01/2010–03/2014
Projektpartner
- TU Ilmenau, FG Neuroinformatik und Kognitive Robotik
- L-1 Identity Solutions AG
- Ruhr-Universität Bochum
- Avistra GmbH
- Flughafen Erfurt – Weimar GmbH
- European Aviation Security Center Schönhagen e.V.
Gesamtzuwendung
2,58 Mio. €
Motivation
Flughafenterminals sind Bereiche mit einem hohen Sicherheitsbedarf, die in den vergangenen Jahren verstärkt mit Videokameras ausgestattet wurden. Die daraus resultierenden Videobilder werden in einem Leitstand von Fachpersonal auf Auffälligkeiten hin analysiert.
Ziele und Vorgehen
APFel hat zum Ziel, dieses Fachpersonal zu unterstützen. Eine sich verdächtig benehmende Person kann auf dem Bildschirm vom Operator markiert werden, um sie dann leichter über mehrere Kameras hinweg auf ihrem Weg im Flughafen im Blick behalten zu können. Die auf diese Weise erfassten Bewegungsspuren werden mit typischen Laufwegen z. B. in einem Flughafen verglichen, um per Vorwärtsanalyse den wahrscheinlichen weiteren Weg vorhersagen zu können. Eine Betrachtung des Weges über mehrere Videokameras hinweg erlaubt es auch, mittels Rückwärtsanalyse die bisher zurückgelegten Wege zu erkennen. Mit diesen Funktionen wird eine frühzeitige Einschätzung des Gefahrenpotenzials von verdächtigen Personen erheblich erleichtert. Die technischen Besonderheiten dieser unterstützenden Videoanalyse führen auch zu spezifischen Fragen im Umgang mit personenbezogenen Daten, die im Vorhaben auch aus datenschutzrechtlicher und grundrechtlicher Sicht untersucht werden.
Themenschwerpunkt des Instituts Informatik der Hochschule Ruhr West war die videobasierte und kameraübergreifende Bildsequenzanalyse, wobei das Ziel bestand, eine schnelle und effektive Ausdünnung des zeitlichen und räumlichen Suchraums auf dem Videomaterial zu realisieren. Hierzu wurde eine schnelle Vorsortierung möglicher kameraübergreifender Personenhypothesen ermöglicht. Das zu entwickelnde System teilt sich dabei in die Aufgabenfelder videotaktschritthaltende Indizierung und die Lokalisation von Personen. Während der Videoindizierung werden erste Informationen wie der Vordergrundbereich, Personendetektionen und erste Personenmerkmale extrahiert. Erst die Lokalisation einer Person, welche nur von einem Operator in einer Gefahrensituation ausgelöst werden kann, beschäftigt sich mit der personenspezifischen Auswertung des Videomaterials.
Ein weiterer Arbeitspunkt des Instituts Informatik war die Bildakquise und -verbesserung sowie die Verteilung der Bilderdaten auf die analysierenden Teilsysteme. Die Hochschule Ruhr-West hat sich maßgeblich in die Systemspezifikation von der Auswahl geeigneter Sensorik bis hin zum individuellen Gesamtsystem eingebracht.

Im Bereich des maschinellen Lernens existieren viele robuste Methoden zur Objekterkennung, Klassifikation von Merkmalen sowie zum Lernen mathematischer Funktionen. Häufig setzt die algorithmische Komplexität der Verfahren, einer praktischen Anwendung deutliche Grenzen.
Ein Beispiel hierfür ist die Objektdetektion mit Hilfe von Histogrammen orientierter Gradienten („HOG Algorithmus“ oder „HOG“), welche auch im APFel Forschungsprojekt eingesetzt wurde. Die Zielsetzung in diesem Kontext war eine videotaktschritthaltende Detektion von Personen in Videoströmen mit 10fps. Obwohl das Verfahren zuverlässig arbeitet benötigt es ca. 60 Sekunden Rechenzeit pro Bild, d.h. für eine Sekunde Videomaterial werden 10 Minuten Rechenzeit veranschlagt. Um dieses Verfahren praktisch einzusetzen wurde ein GPU basierter Algorithmus entwickelt und effizient implementiert. Dadurch konnte die Verarbeitungsdauer pro Bild auf ca. 60ms reduziert werden, d.h. mit Hilfe einer einzelnen GPU können bis zu 16 Bilder pro Sekunde verarbeitet werden.
Eine weitere Herausforderung bestand darin Videoströme multipler Kameras zu verarbeiten, ein einzelner dedizierter Rechner stößt hierbei schnell an seine Grenzen. Hierzu wurde ein Beowulf Cluster aus 15 performanten PCs mit insgesamt 20 Grafikkarten konzipiert und aufgebaut. Weiterhin wurde ein Software Framework entwickelt, welches erlaubt die Videodaten auf mehreren Rechenknoten parallel zu verarbeiten (Abb. 1). Ein dedizierter Management Knoten verteilt hierbei die Last balanciert auf die verfügbaren Rechenknoten. Der Cluster bietet in der derzeitigen Ausbaustufe eine synthetische Leistung von 107 TFlops auf GPU-Basis und 2 TFlops auf CPU-Basis, in Bezug auf die Personendetektion ist er in der Lage 34 parallele Videoströme mit 10fps zu verarbeiten und skaliert linear mit der Anzahl verfügbarer Rechenknoten (Abb. 2 zeigt drei Rechenknoten des Gesamtsystems).
Häufig werden Personendetektoren auf Basis generischer Daten trainiert, dies erlaubt den Einsatz auf allgemeinen Bilddaten, reduziert jedoch die Zuverlässigkeit sowie Robustheit in sehr speziellen Situationen. Als Beispiel sei Abb. 3 betrachtet, hierbei wird nur ein geringer Teil von Personen detektiert. Durch die Hinzunahme von Expertenwissen in Form von kameraspezifischen Trainingsdaten kann die Detektionsgüte erheblich gesteigert werden (Abb. 4). Werden zusätzlich geometrische Daten zur Kameraperspektive hinzugenommen, so ergibt sich eine weitere Erhöhung der Detektionsqualität. Ein Beispiel ist in Abb. 5 aufgeführt, hierbei wird die Person im Vordergrund nicht detektiert, durch eine positionsbezogene Skalierung der Klassifikationsparameter wird diese jedoch detektiert (Abb. 6).
Eine weitere Steigerung ergibt sich durch die Fusion multipler Detektoren wie z.B. Oberkörper-Detektor und Kopf-Detektor, die Resultate diesbezüglich werden deutlich beim Betrachten des Vergleichsvideos. Die linke Seite des Videos zeigt den naiven Ansatz mit einem einzelnen Detektor für den Oberkörper, auf der rechten Seite des Videos ist deutlich zu sehen wie stark die Ergebnisse durch die Fusion von Kopf- und Oberkörper Detektor verbessert werden.
Ein weiteres Forschungsgebiet des Instituts Informatik sind verteilte Large-Scale GPU-basierte künstliche neuronale Netze mit evtl. dynamischer Topologie. Künstliche neuronale Netze können eine große Vielfalt an Aufgaben erfüllen, sei es die Klassifikation von abstrakten Merkmalen, das Lernen unbekannter mathematischer Funktionen oder die Abschätzung von Wahrscheinlichkeiten. Seit langer Zeit wird untersucht auf welche Art verschiedene neuronale Netze effizient trainiert werden können. In den letzten Jahren stieg jedoch das Datenvolumen wesentlich stärker an als die (auf einem Rechner) zur Verfügung stehende Rechenleistung. Dieser Umstand wird häufig durch massive Parallelisierung adressiert, sei es durch GPU-basierte Lösungen oder einer Verteilung des Netzes in Clustern. Jedoch erfordern solche Lösungen die Entwicklung neuer Algorithmen und Systemstrukturen, insb. im Hinblick auf GPU-basierte Berechnungen. Wesentliche Schwerpunkte am Institut sind hierbei:
- Effiziente Kommunikation zwischen u.U. fragmentierten Netzen.
- Aufteilung von neuronalen Netzen in Rechenclustern.
- Entwicklung generischer Software Strukturen für Rapid Prototyping in Bereich verteilter neuronaler Netze.
- Effiziente Algorithmen für verteiltes Training neuronaler Netze.
- Effiziente (hybride) Algorithmen für GPU basiertes (lokales) Training.
- Untersuchung diverser Arten neuronaler Netze wie z.B. vollständig verbundene Netze, Deep Belief Netze oder rekurrente Netze im Hinblick auf massive Parallelisierbarkeit und Verteilung in Clustern
- Untersuchung von Netzen mit dynamischer Topologie im Hinblick auf massive Parallelisierbarkeit und Verteilung in Clustern

Zur umfangreichen Ausstattung des Labors für Bildverarbeitung gehören auch mehrere Kameras für Hochgeschwindigkeitsaufnahmen. Hierzu zählen Kameras des Typs ActionPro x7 (Abb. 1) sowie AVT Bonito CL-400C (Abb. 2). Aufgrund der kompakten Bauweise sowie einfachen Bedienung der x7 ist es möglich die Kamera in einer Vielzahl interessanter Schülerprojekte einzusetzen. Somit können bereits Schüler erste Schritte im Bereich der Bildverarbeitung sehr schneller optischer Vorgänge vornehmen (die x7 Kamera zeichnet mit bis zu 240fps auf). Für wissenschaftliche Untersuchungen, Forschung sowie Lehre wird die Bonito CL-400C eingesetzt. Diese Kamera zeichnet hochauflösende Bildsequenzen mit 400fps auf und ermöglicht dadurch eine detaillierte Untersuchung extrem flüchtiger Ereignisse. Somit können z.B. innerhalb von Videoströmen neue Merkmale für Verfahren zur Objektdetektion extrahiert werden. Im Bereich der Lehre bietet diese Kamera eine Grundlage für studentische Projekte wie z.B. Untersuchung effizienter Algorithmen zur Verarbeitung großer Datenmengen oder den Aufbau von Versuchen zur präzisen (trigger-basierten) Aufzeichnung stochastischer Vorgänge. Zur Verarbeitung der großen anfallenden Datenmengen wird ein adäquater Computer mit 256GB Arbeitsspeicher und 24 CPU Kernen bereitgestellt.

Am Institut Informatik werden sogenannte intelligente Kameras der Firma Matrix Vision eingesetzt, um verschiedenste Bildverarbeitungsaufgaben zu lösen. Ausgestattet mit ARM-Prozessoren werden die Videodaten direkt von den Kameras verarbeitet und leiten nur noch die Ergebnisse der Analyse weiter. So können sie z. B. zur optischen Qualitätskontrolle in industriellen Anwendungen eingesetzt werden und liefern einen wichtigen Beitrag zur Automatisierung von Fertigungsprozessen. Zwar ist die Rechenleistung nicht mit der von gängigen Computern vergleichbar, dennoch stellen intelligente Kameras in Verbindung mit einfachen Bildverarbeitungsmodulen eine hochwertige und vielseitig einsetzbare Sensorik dar. Über eine entsprechende Schnittstelle (100 MBit Ethernet) lassen sich die Kameras auf einfache Weise in bestehende Netzwerkstrukturen integrieren. Kommunikation und Datentransfer erfolgen über eine klassische TCP/IP-Schnittstelle. Die Kameras lassen sich mittels SDK programmieren und unterstützen dabei verschiedene Programmiersprachen, wie z. B. C/C++, C# und VB.NET.
Anwendungsbeispiele:
- Aussortierung von Schlechtteilen in der Fertigung
- Risserkennung bei der Herstellung von Pressteilen
- Barcode-Scanner zur Identifikation von Objekten

Für Mensch-Mensch ähnliche Mensch-Roboter Interaktion muss emotionale Interaktion betrachtet werden. Die Aufgabe der Erkennung von menschlichen Emotionen anhand automatischer Systeme ist hier herausgefordert. Erkennung von Emotionen basiert auf die Analyse von verschiedenen menschlichen Merkmalen, äußerlich wie Gesicht, Stimme und Körperbewegungen, oder innerlich wie Herzpulse, Muskeln Aktivitäten, Elektrokardiogramm und Elektroenzephalografie. Für neutrale und Kontaktlose Interaktion sind Gesicht und Stimme betrachtet, die keine physische Verbindung zu dem Roboter und zu jeglichen Sensor, wie im Falle der innerlichen Merkmalen.
Gesichtsausdrücke könnten die meist geforschten und angewandten Merkmale für die Erkennung von Emotionen sein. Im Gegensatz zu anderen Systemen das entwickelte System analysiert die Emotionen echtzeitlich in realen Umgebungen. Das System führt alle Schritte der Emotionserkennung voll automatisch und ohne weitere zusätzliche Initialisierung, wie Malen von Punkten auf das Gesicht und Fixierung des Gesichts vom Interaktionspartner auf feste Position.
Weil natürliche Mensch-Roboter Interaktion in Real-Life Abschnitte enthält, in denen das Ausdrücken von Emotion per Gesichtsausdrücke durch den Mechanismus des Sprechens beeinträchtigt ist, ist das erzeugte akustische Signal als Komplement betrachtet. Es ist so realisiert, dass Gesichtsbilder und akustische Informationen des Benutzers gleichzeitig aufgenommen, bearbeitet und fusioniert. Das fusionierte System liefert bessere Erkennungsraten im Vergleich zu den einzelnen Gesicht-Bilder- und Akustische-Signal-basierte Systeme.

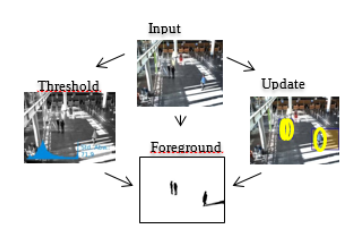
In Sicherheitsszenarien werden in der Regel verschiedene Methoden eingesetzt, um Videodaten zu analysieren. So kommen z. B. Verfahren wie Bewegungsdetektion, Hintergrundsegmentierung, Personendetektion etc. zum Einsatz. Diese Verfahren funktionieren je nach Szenario unterschiedlich gut. Auf Bildern mit einem homogenem Hintergrund liefert bspw. das etablierte HOG-Verfahren [1] sehr gute Ergebnisse. Weisen die Bilder jedoch eine große Struktur auf (viele horizontale und vertikale Linien), werden verfahrensbedingt viele Falsch-Positiv-Detektionen erzeugt (Bspw. Abb. 2 Bild links). Um bessere Ergebnisse zu erzielen und Falsch-Positiv-Detektionen zu reduzieren, werden die Ergebnisse der einzelnen Module kombiniert. Die Fusion der Module kann auf unterschiedlichen hierarchischen Level erfolgen. Es existieren verschiedene Ansätze, um Daten zu fusionieren [2]. Das Institut Informatik verfolgt einen entscheidungsbasierten Ansatz. Im Falle einer Personendetektion wird nach Überschneidungen mit anderen Verfahren gesucht. Dabei wird ein entsprechender Score berechnet. Ein zuvor gesetzter Schwellwert entscheidet dann darüber, ob es sich um eine positive Detektion handelt (vgl. Abb. 1). Wird bspw. eine Person detektiert, obwohl diese Region nicht Teil des Vordergrunds ist und dort keine Bewegung registriert wird, dann ist die Wahrscheinlichkeit, dass es sich um eine Falsch-Positiv-Detektion handelt, sehr hoch. In so einem Fall wird die Personendetektion verworfen. Eine weitere Möglichkeit ist die Kombination von Kopf- und Personendetektionen. Dabei werden diejenigen Personendetektionen verworfen, in deren oberen drittel kein Kopf detektiert wurde. Das Verfahren ermöglicht eine ganze Reihe weiterer Kombinationsmöglichkeiten, so lassen sich z. B. Oberkörper- mit Kopfdetektionen oder Kopf- und Gesichtsdetektionen fusionieren. Da die Ergebnisse der Einzelmodule dem Entscheidungsprozess bereits vorliegen und nicht erst berechnet werden müssen, nimmt die Ausführung der Fusion eine vernachlässigbar geringe Zeit in Anspruch. Das Ergebnis des Fusionsprozesses ist eine erhebliche Reduzierung von Falsch-Detektionen, was die Zuverlässigkeit erhöht und zu einer Steigerung der Robustheit des Gesamtsystems führt. Es werden zwar nicht in allen Szenarien sämtliche Falschdetektionen eliminiert, das Gesamtergebnis ist gegenüber den Einzelergebnissen jedoch wesentlich besser. Ein Beispiel des Fusionsprozesses ist in Abb. 2 zu sehen. Hier werden die Ergebnisse der Bewegungsdetektion, der Hintergrundsegmentierung und der Personendetektion fusioniert, was zu einer Eliminierung sämtlicher Falsch-Positiv-Detektionen führt.
Die Anwendung dieses Verfahrens zeigt das Potenzial von Fusionsverfahren. Die beschriebene Methode ist jedoch davon abhängig, dass ein möglichst robuster Personendetektor eingesetzt wird, der sämtliche Personen auf einem Bild findet. Schlägt der Detektor nicht an, findet keine Fusion statt. Das Institut Informatik hat das Verfahren deshalb dahingehend weiterentwickelt, dass auch diejenigen Personen gefunden werden, die nicht durch den Detektor ermittelt werden. Um dies zu erreichen, wird in einem nächsten Schritt jedes Verfahren unterschiedlich gewichtet. Eine geeignete Gewichtung wird dabei durch eine Verfahrensevaluation ermittelt. Die Erweiterung des Fusionsprozesses ist in Abb. 3 dargestellt. Jeder Pixel einer ROI wird entsprechend gewichtet, wobei die Gewichte übereinanderliegender ROIs aufsummiert werden. Markiert werden dann diejenigen Bereiche, die über einem spezifizierten Schwellwert liegen. Das Ergebnis ist eine Aufmerksamkeitskarte (rechts im Bild). Durch diese Erweiterung wird eine Unabhängigkeit von der Personendetektion erreicht bei gleichzeitiger Eliminierung von Falsch-Positiven.
Quellen:
[1] N. Dalal and B. Triggs, „Histograms of oriented gradients for human detection“, in CVPR 2005, vol. 1, pp. 886–893.
[2] B. V. Dasarathy, Decision Fusion. Los Alamitos: IEEE Computer Society Press, 1994.
Ziel dieser Arbeit ist die Entwicklung einer modellbasierten, generischen Wiedererkennung von Personen. Auf Basis von experimentell erhobenen Gangdaten soll ein Modell entwickelt und dessen Parameter mit Hilfe eines Optimierungsverfahrens, z. B. unter Anwendung evolutionärer Algorithmen, bestimmt werden. Die gefundenen Modellparameter sollen die Gangart des Individuums charakterisieren und unterscheiden. Das im Rahmen der Promotion zu entwickelnde Modell leistet einen Beitrag zur Analyse der Kinematik von Personen. Dies ist z. B. in der Sicherheitsforschung relevant, denn die Wiedererkennung von Personen ist vor allem in sicherheitskritischen Bereichen von großer Bedeutung. Entsprechende Systeme werden z. B. an Flughäfen, Stadien bzw. allgemein an öffentlichen Plätzen mit hohem Personenaufkommen eingesetzt. Ein häufig eingesetztes Verfahren ist die Gesichtserkennung, welche jedoch in vielen Fällen problematisch ist, so z. B. bei geringer Auflösung oder Aufnahmen, bei denen das Gesicht nur teilweise zu sehen ist. Hier greift die Erkennung der Gangart und kann sowohl als alleiniges Merkmal als auch in Verbindung mit anderen biometrischen Erkennungsverfahren genutzt werden. Die Identität einer Person lässt sich nicht nur anhand äußerlicher Merkmale oder der Stimme festlegen, sondern kann auch anhand der individuellen Gangart erfolgen. Signaturen in menschlichen Bewegungsfolgen sind einzigartig und haben das Potential, einzelne Personen anhand des charakteristischen Bewegungsmusters zu erkennen. Erste Ansätze zur Erkennung am Gang wurden in den 90er Jahren entwickelt. Grob lassen sich die verschiedenen Ansätze in modell-freie und modell- basierte Ansätze unterscheiden [1, 2]. Die Personenerkennung am Gang unterscheidet sich als kontaktloses Verfahren von allen anderen biometrischen Methoden. Übliche Verfahren untersuchen Gesicht, Fingerabdruck, Iris, Sprache, etc. Nachteil dieser Methoden ist, dass eine Kooperation der Personen notwendig ist. Zur Identifizierung von Personen anhand ihres Bewegungsmusters bedarf es keiner besonderen Aktionen seitens der Zielpersonen. Die Identifikation ist berührungslos und unauffällig und kann nur schwer von der Person verhindert werden. Weiterhin können Personenbewegungen auch aus großer Entfernung und bei geringer Auflösung detektiert werden. Die Gangart ist ein junges biometrisches Verfahren, das nicht unter den genannten Nachteilen leidet. Allerdings gibt es auch einige Randbedingungen, die die Identifizierung von Personen anhand ihrer Gangart einschränken (bspw. Untergrund, Traglast, Geschwindigkeit).
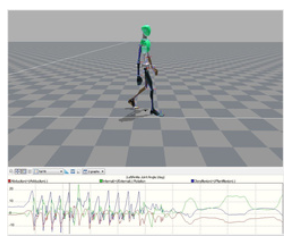
Das angestrebte Modell erfordert eine exakte Positionsbestimmung der menschlichen Gelenke. Hierfür ist der Einsatz eines Motion Capture Systems aufgrund der Genauigkeit besonders gut geeignet. Bei dem am Institut Informatik vorhandenen System der Firma Xsens handelt es sich um ein Inertialsystem, das auf Trägheit basierende Sensoren verwendet, um die 3D-Position im Raum zu bestimmen. Die Sensoren werden mit Hilfe von Klettverschlüssen am Körper befestigt und ermöglichen den Probanden maximale Bewegungsfreiheit. Dadurch können natürliche Bewegungsabläufe aufgezeichnet werden und die Sensoren können nicht sichtbar unter der Kleidung getragen werden. Die aufgezeichneten Bewegungsdaten werden einem menschlichen Modell zugeordnet (Abb. 1).
Neben der Anwendung in Sicherheitsszenarien ist die Bewegungsanalyse auch in nicht-sicherheitsrelevanten Anwendungen von Bedeutung. Ein Beispiel ist die Robotik bei der Entwicklung von humanoiden Robotern, deren Gang an den des Menschen angeglichen wird. In der Medizin kann die Analyse von Bewegungsmustern bei der Diagnose von Krankheiten unterstützen oder zur Sturzprävention eingesetzt werden. Werden der Gang bzw. die Körperbalance „schlechter“, steigt das Risiko von Stürzen. Während die medizinische Forschung i. d. R. in einem Labor stattfindet, bietet das Motion Capture System die Möglichkeit, die Personen bei der Durchführung von Alltagsbewegungen aufzuzeichnen. Weiterhin findet die Bewegungsanalyse in der Film- und Spieleindustrie Anwendung, da sich hier animierte Menschen (Avatare) realistisch bewegen müssen.
Quellen:
[1] Mark S. Nixon and John N. Carter. Automatic recognition by gait. Proceedings of the IEEE, 94:2013–2024, 2006.
[2] Nikolaos V. Boulgouris, Dimitrios Hatzinakos, and Konstantinos N. Platanio- tis. Gait recognition: A challening signal processing technology for biometric identification. IEEE SIGNAL PROCESSING MAGAZINE, 22:78–90, 2005.

In der digitalen Bildverarbeitung ist man auf informationsreiche Aufnahmen angewiesen um die gewünschten Informationen zu extrahieren. Naturgemäß stellen daher Bildverbesserungsverfahren ein grundlegendes Forschungsfeld des Labors dar. Ein besonders großes Spektrum an Informationen liefern HDR-Bilder. Diese können durch Kombination zweier LDR-Bilder, mit hoher und geringer Belichtungszeiten, derselben Szene erreicht werden, aber auch die direkte Aufnahme solcher Bilder ist mit heutigen Kameras möglich. Die daraus resultierende Datenmenge stellt für viele Verfahren der Bildverarbeitung allerdings einen immensen Mehraufwand dar, weshalb häufig auf die größere Dynamik verzichtet wird.
Um dennoch eine hohe Dynamik zu erhalten, können spezielle Abbildungsfunktionen verwendet werden. Um Beleuchtungsschwankungen auszugleichen passen Kameras die Belichtungszeit an. Hierbei wird meist versucht eine vorgegebene mittlere Helligkeit des Bildes zu erreichen. Aus der Kombination beider Ansätze wurde im Labor Bildverarbeitung ein Algorithmus entwickelt, welcher zunächst überlichtete Bereiche sucht und die Belichtungszeit so lange reduziert bis diese Bereiche verschwunden sind, bzw. die Belichtungszeit wird erhöht bis kurz vor der Sättigung einzelner Bildbereiche. Anschließend kann aus der resultierenden mittleren Helligkeit und der avisieren mittleren Helligkeit des Bildes der Parameter einer Gammakorrektur berechnet werden, welche zur Abbildung des HDR-Bildes auf ein LDR-Bild verwendet wird. Das resultierende Bild enthält nun Informationen aus den hellen wie auch aus den dunklen Bildbereichen.
Eine häufige Aufgabe im Rahmen der Bildverarbeitung ist die Detektion interessanter Bildbereiche. Häufig sind dies spezielle Objekte oder Objektklassen. Zu den schnellsten Verfahren zur Detektion von bewegten Objekten zählen die Vordergrundseparierung oder auch die Bewegungsextraktion. Beide Verfahren detektieren aber nur Veränderungen im Bild, eine eindeutige Zuordnung zu einer Objektklasse ist damit nicht möglich. Hierzu wurden spezielle Detektoren entwickelt, zu den bekanntesten gehören die Addboost-Detektoren und die HOG-Detektoren. Die HOG-Detektoren sind dabei die heute am häufigsten eingesetzten Detektoren, da diese auch in anspruchsvollen Situationen eine sehr gute Erkennungsleistung liefern können. Diese benötigen aber große Rechenkapazitäten, was keinen videotaktschritthaltenden Einsatz, ohne Spezialhardware oder einschränkenden Rahmenbedingungen, auf hochaufgelösten Bildern ermöglicht. Im Labor Bildverarbeitung wurde daher eine Kombination mit den schnellen Verfahren entwickelt.
Zunächst werden mittels adaptiver Vordergrundanalyse die Bereiche des Vordergrundes extrahiert in welchen sich die interessanten Objekte befinden. Hierbei wird das aktuelle Bild mit einem Hintergrundmodell verglichen, wobei eine geringe Abweichung erlaubt sein muss um Rauschen oder Lichtschwankungen auszugleichen. Diese Abweichung kann mittels der Standardabweichung über das Bild ermittelt werden, was die Anpassung an die jeweilige Bilddynamik erlaubt. Nun operiert der eigentliche Detektor nur in den bereits stark eingeschränkten Bereichen. Dadurch reduziert sich die Bildgröße aber auch die möglichen zu betrachtenden Parameter des Detektors wodurch dieser auch mit gängigen CPUs videotaktschritthaltend operieren kann.
Damit ein Vordergrunddetektor auch bei sich ändernder Beleuchtung oder Änderung des Hintergrundes operieren kann muss das Hintergundmodell adaptiert werden. Hierbei können nicht oder nur langsam bewegende Objekte in den Hintergrund verlagert werden. Um dies zu vermeiden wird eine Rückkopplung der Detektionsergebnisse verwendet, so dass nur die Bereiche des Hintergrundmodells aktualisiert werden in denen keine interessanten Objekte detektiert wurden.
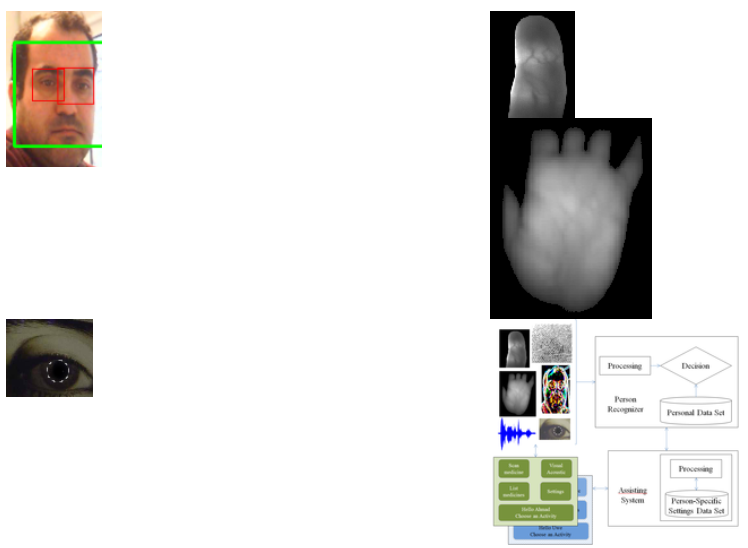
Hier stellen biometrische Systeme und ihre Anwendungen im häuslichen Umfeld die Forschungsschwerpunkte dar. Erforscht werden sowohl die Eignung und die Effizienz jeglicher biometrischen Merkmale im alltäglichen Einsatz Zuhause als auch die Fusionsmöglichkeiten von verschiedenen Merkmalen in einem multimodalen System, welches sich robuster verhält und bessere Erkennungsraten liefert.
Reale Szenarien wie Personen-spezifische Nutzer-Umgebungsinteraktion, Assistenz-Systeme für das häusliche Umfeld im Allgemeinen und insbesondere medizinische Assistenz-Systeme - sowie die Integration solcher Systeme in alleinstehenden eingebetteten Systeme - werden auch erforscht.

Das Institut Informatik verfügt über eine Wärmebildkamera, die für das menschliche Auge unsichtbare Wärmestrahlung sichtbar macht. Wärmebildkameras zeichnen langwellige Infrarotstrahlung (0,9 µm bis 14 µm) auf. Dabei wird die Intensität der Strahlung von Oberflächen gemessen. Je nach Anwendung kommen unterschiedliche Sensoren zum Einsatz. Siliciumsensoren werden für kürzere Wellenlängen verwendet, längere Wellen hingegen mit Gallium-Arsenid-Sensoren. Die Messungen können über große Entfernungen erfolgen und sind komplett berührungslos. Ein weiterer großer Vorteil ist, dass die Geräte auch bei völliger Dunkelheit eingesetzt werden können. Sie eignen sich somit für Überwachungsszenarios. Die am Institut Informatik befindliche Kamera verfügt über eine Auflösung von 320x240 Pixel im Infrarotbereich. Die integrierte Digitalkamera hat eine Auflösung von 2048x1536 Pixel. Es können Temperaturen im Bereich von -20° C bis +650° C gemessen werden. Die Genauigkeit beträgt dabei ± 2° C. Wärmebildkameras bieten ein breites Spektrum an Einsatzmöglichkeiten.
Anwendungsbeispiele:
- Sicherheitsanwendungen (Detektion von Personen in Nachtszenarios)
- Gebäudeuntersuchung auf Schwachstellen in der Isolierung (Wärmeverluste)
- Verfahren zur Materialprüfung
- Diverse Einsatzmöglichkeiten für die Feuerwehr (durch Rauch hindurch sehen)

Im Forschungsbereich "Neuronale Lernmethoden für die Mensch-Maschine-Interaktion" werden neu entwickelte und biologisch inspirierte Techniken des maschinellen Lernens angewendet, um die Mensch-Maschine-Interaktion durch robuste Wahrnehmung des menschlichen Handelns zu verbessern. Dabei werden m
oderne 3D-Sensoren mit ToF-Technologie (Time-of-flight) verwendet, die eine zuverlässige Datenerfassung und Verarbeitung unter schwierigen Umgebungsbedingungen in Echtzeit ermöglichen. Das spezifische Ziel dieses Bereiches Projektes ist es, die Erkennungsrate von Handgesten im dreidimensionalen Raum zu verbessern, wobei auf adaptive Weise die Gesamtheit des menschlichen Ausdrucks (d.h. nicht nur der aktuellen Handgeste) und ergänzende Informationen weiterer Sensoren berücksichtigt werden.
Der vorgestellte Ansatz beruht auf aktuellen Forschungsthemen wie Multisensorfusion und maschinelles Lernen und kombiniert diese mit neuen innovativen Bedienkonzepten wie die berührungslose Interaktion durch Handgesten in den dreidimensionalen Raum. Dabei wird durch Korrelationen der Datenräume komplementärer Sensoren eine datengetriebene Fusion erreicht.

Aufgrund rascher Fortschritte auf dem Feld der 3D-Technologien ist es möglich, neue Anwendungsgebiete zu erschließen. Im Rahmen des beantragten Forschungsprojekts soll ein Smart-Control-Device (SCD) entwickelt werden, welches mittels 3D-Kamera Benutzergesten erkennt, diese interpretiert und zur Steuerung von Systemen einsetzt. Des Weiteren soll das SCD so konstruiert werden, dass es sich robust gegenüber Störungen zeigt und flexibel in wechselnden Umgebungen einsetzbar ist.
Ziel des Projekts ist es, durch die Beobachtung und Analyse der Umgebungsszene Handgesten des Benutzers zu erkennen, zu interpretieren und weiterzuverarbeiten. Moderne ToF-Technologie (Time-of-Flight) misst die Laufzeit des ausgesandten Lichts von der Steuereinheit zu Zielobjekten und erstellt mit diesen Daten ein 3D-Tiefenbild. Diese Technologie ist so robust gegen Außeneinwirkungen, dass sie problemlos in verschiedenen Szenarien, sowohl im Außenbereich als auch im Innenraum, einsetzbar ist.
Das SCD wird als Produkt mit einer ToF-Kamera und einer Mikrocontrollereinheit produziert - hierdurch reduziert man dessen Gesamtvolumen und macht es so z.B. in Automotive-Bereichen einsetzbar. Die Kombination dieser Technologien erlaubt es dem Benutzer, berührungsfrei mit dem SCD zu interagieren, eigene benutzerabhängige Gesten aufzunehmen und zu lernen. Nach außen geführte Schnittstellen erlauben die direkte Kopplung mit anderen Systemen.
In Kooperation zwischen der Hochschule Ruhr West (HRW) und der NISYS GmbH soll ein Demonstrator entwickelt werden, welcher die beschriebenen Anforderungen erfüllt. Die NISYS GmbH kann hierbei auf langjähriges Know-How in der Entwicklung von Softwarekomponenten für PC und eingebettete Systeme zurückgreifen.

Im Bereich der Bildverarbeitung gibt es verschiedenste Problemstellungen unter anderem die Bestimmung von Oberflächeneigenschaften. Neben dem gebräuchlichen Einsatz von Farb- und Texturmerkmalen im sichtbaren Bereich eigenen sich häufig auch weitere Lichtspektren zur Beschreibung eines Objektes. Häufig liefern diese Spektralbereiche ergänzende Informationen. So lassen sich im UV-Bereich zum Beispiel Materialschwächen erkennen und im FIR-Bereich kann Wärme ausgemacht werden. In den letzten Jahren hat sicher allerdings ein weiterer Spektralbereich als äußerst informationsreich herausgestellt. Der Bereich von 900nm-1700nm schließt sich im infraroten Wellenspektrum direkt an das sichtbare Licht an (350nm – 950nm) und wird als nahinfrarotes (NIR) oder auch kurzwelliges infrarotes Spektrum (SWIR) bezeichnet. Dieses Wellenspektrum ist deshalb interessant, weil sich die Reflexion verschiedener Materialien in diesem Spektrum unterscheiden. Über die lose Erscheinung einer Oberfläche hinaus lassen sich so verschiedene Materialien von Oberflächen unterscheiden. Beispielsweise ist der Füllstand einer Wasserflasche aus Weißglas nur sehr schwer im visuellen Bereich zu ermitteln. Im SWIR-Bereich ist die Falsche allerdings immer noch transparent, das Wasser hingegen ist schwarz. Als konkretes Anwendungsbeispiel wird im Labor die in Abbildung 1 dargestellte Kombination von RGB- und SWIR-Kameras zur Wiedererkennung von Personen verwendet. Wie in der Abbildung zu sehen unterscheiden sich Kleidungsstücke derselben Farbe und Textur im SWIR-Spektrum teilweise erheblich wenn diese eine andere Materialzusammensetzung haben. Dies erlaubt häufig eine Diskriminierung, wenn rein visuelle Merkmale versagen.

Die zuverlässige Wiedererkennung von Personen in natürlicher Umgebung stellt, auf Grund der hohen Komplexität der Szenerie und der Veränderlichkeit von Personen, noch immer eine große Herausforderung dar. Um Personen in den verschiedensten Szenarien wiedererkennen zu können ist daher die Kombination multipler Merkmalssets und Vergleichsalgorithmen notwendig. Aus diesem Grund befasst sich das Labor Bildverarbeitung mit einem breiten Spektrum an Wiederkennungsverfahren und betrachtet dabei auch stets die Möglichkeiten der Fusion.
Das Labor Neuroinformatik befasst sich daher unter anderem mit der kameraübergreifenden Wiedererkennung von Personen anhand von Kleidungsmerkmalen. Hierbei liegt der Fokus auf der automatisierten Extraktion individueller Merkmale. Und deren zeitlichen Verknüpfung zu individuellen Personenmodellen. Hierbei werden körperteilbezogen Merkmale wie der mittlere Farb- und Sättigungswert sowie entsprechende Histogramme und die Stärke der Texturierung mit individuellen, auffälligen Merkmalen kombiniert. Auffällige Merkmale werden durch Verfahren lokalisiert, welche lokale Abweichungen von der Umgebung detektieren, wie die lokale Entropie, lokale co-occurrence Matrizen oder den Aufmerksamkeitskarten von Itti und Koch. Durch Kombination verschiedener Sensoren (z.B. RGB- und NIR-Kameras) lässt sich dabei der Merkmalsraum noch weiter erhöhen.

Es ist eine alltägliche Erfahrung, dass wir Urteile über gut oder schlecht, bzw. qualitativ hochwertig oder minderwertig eines Gegenstandes mit der Wahrnehmung des emittierten Geräuschschalls in Verbindung bringen. Dieser sogenannte Geräuschlaut ist deshalb ein wichtiges Entscheidungskriterium bei der Auswahl eines Produktes, welches wahrnehmbaren Schall erzeugt (Soundqualität). Beispielsweise wird das von einem Kraftfahrzeug erzeugte Geräusch einerseits an die Umgebung abgestrahlt und von Anwohnern, Straßenpassanten und anderen Verkehrsteilnehmern wahrgenommen. Für diese Hörergruppen geht der Schall scheinbar von unkontrolliert vorbeifahrenden anonymen Geräuscherzeugern aus. Da keine direkte Einflussnahme möglich ist, fühlen sich Personen aus dieser Gruppe mehr oder weniger belästigt. Andererseits ist das Geräusch auch im Innenraum des Kraftfahrzeuges hörbar. Dort erfüllt das Geräusch für den Fahrzeuginsassen unter anderem eine Kontrollfunktion und trägt entscheidend zur Zufriedenheit bei.
Ziel des Forschungsbereichs Psychoakustik ist deshalb Schallemissionen, dergestalt zu adaptieren (Sounddesign), dass diese zielgruppenspezifischen Anforderungen genügen. Eine Veränderung des Schalldruckpegels in Kombination mit einer Anpassung einzelner Spektralanteile des emittierten Geräuschs kann beispielsweise das Hörempfinden beteiligter Interessengruppen entscheidend verändern.
Die vorhandene Ausstattung des Labors im Bereich der Psychoakustik bildet deshalb die Grundlage um anwendungsbezogene Forschung und Lehre im Bereich Soundqualität und Sounddesign durchzuführen.